With the emergence of Deep Learning, Neural Networks predictive capacity looks extremely promising. This can be seen in the amazing number of theoretical works and applications in the field in the last years, reaching precisions never observed before.
The objective of the article is twofold, first we present a new dataset of rooftop obtained from satellites images. The set is composed of 3000 labeled images of different size, quality and type of rooftop . Second we show that with a simple deep learning architecture we are capable to identify different rooftop types with high accuracy as high as 98%.You can download images, scripts model, and weights here
The dataset is distributed as follows:

- Class 1: simple rooftops oriented horizontally.
- Class 2: simple rooftops oriented vertically.
- Class 3: industrial and building roofs.
- Class 4: complex rooftops.
Our program is built upon Keras and TensorFlow on backend. The running time of program may vary, depending on the hardware. On an Intel i7/i5 the running time is on the order of 8 and up to12 hours, as a comparison if the calculation is carried out on a graphic board Nvidia GTX1080ti the running time is reduced to less than 5 minutes. As the running time might be long depending on your hardware configuration, you will find on the downloadable folder the model and weight files (model.hdf5 and best_weigth.hdf5).
Libraries import
import glob import os from os.path import basename import numpy as np import pandas as pd from PIL import Image import keras from keras import optimizers from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D,ZeroPadding2D from keras.callbacks import ModelCheckpoint from sklearn.cross_validation import train_test_split
Extract data, transform to a standard size and loaded to Keras format
path="C://rooftop-detection//"
#load labels
labels= pd.read_csv(path +"labels.csv", delimiter=",",header = None)
#load rooftop image and resize
L=[]
train=np.array([])
images=glob.glob(path +"images"+"/*.*") #importation de images
for i in range(0,len(images)):
im = Image.open(path +"images//"+labels.iloc[i][0]+".jpg")
im_rz=im.resize((64,64), Image.ANTIALIAS)
#im_rz.save(path+"//resized//"+basename(images[i]), 'JPEG',quality=100,optimize=True) #optionally if you want to save rezized images
L.append(np.array(im_rz))
data=np.array(L)
#transformation of labels into categorial variables to be interpreted by keras
y=pd.get_dummies(labels.iloc[:,1])
#seperate data into training set and test set
x_train, x_test, y_train, y_test = train_test_split(data,y, train_size=0.8)
batch_size = 128
nb_classes = 4
epochs = 150
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
y_train=np.array(y_train).astype('float32')
y_test=np.array(y_test).astype('float32')
x_train /= 255
x_test /= 255
Convolutional Neural Network architecture
The architecture is relatively simple: four main blocks all using the activation function “ReLU” and the optimizer used is “RMSpro”.
Notes: Multiple choices of activation function and optimizer are available on Keras (cf: Optimizers)
Each block is composed of two convolution layers where the following operations are defined:
- Filter: neuron number with their weights.
- Stride: pixel number jump at each displacement of the receptive field which evolve within the image.
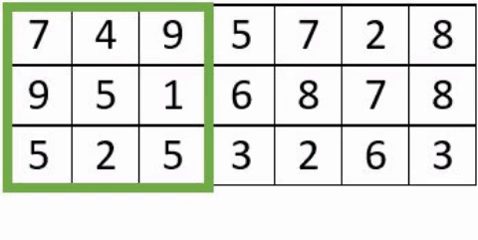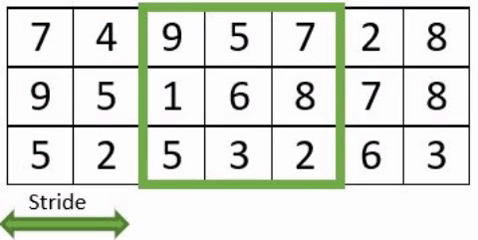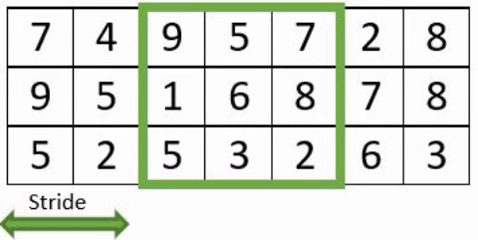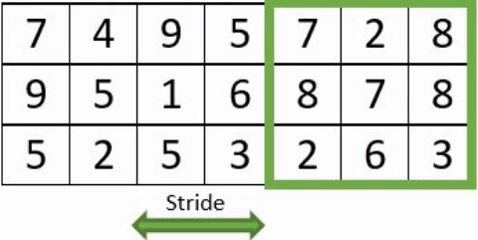
- Padding: artificial extra pixels added to the image to avoid to lost information on image edge.

- Pooling: aggregation of the information allowing reducing the number of variables. Several ways exist to do the reduction; here there are some of them:
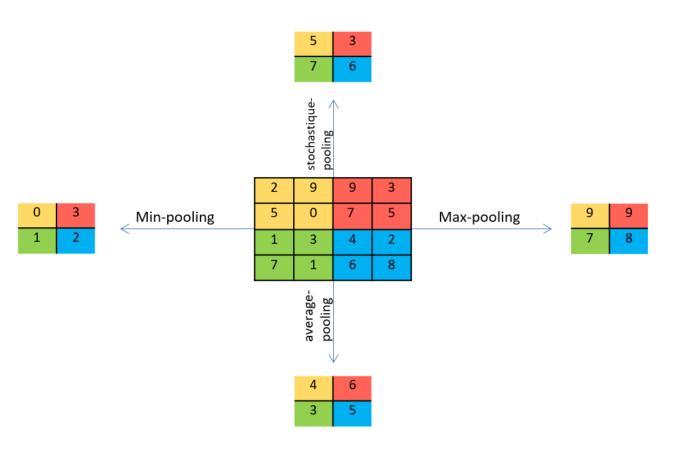
The pooling operation might be interpreted as an operation which lead in a loss of information. But actually there is a tradeoff. For instance the padding add zero pixel around the image in keras, a layer of Maxpooling will delete all this noise, so as to keep only the most relevant information.
- Dropout
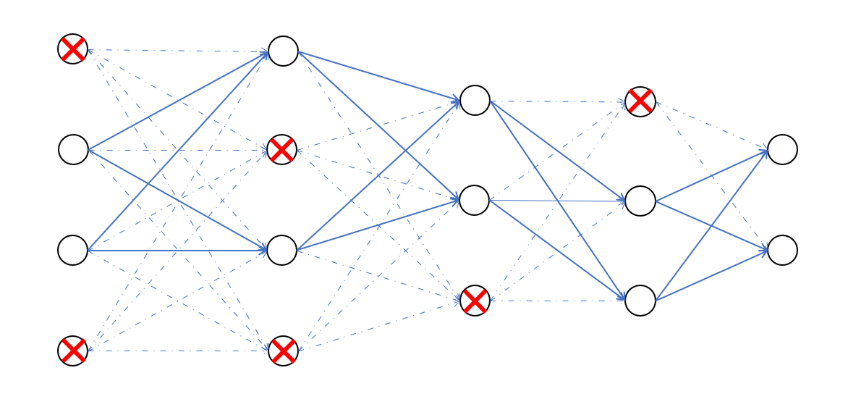 At each training stage some nodes are “dropped out” randomly and temporarily. This strategy has the effect of reduce overfitting. The percentage of nodes to dropout is fixed on Keras.
At each training stage some nodes are “dropped out” randomly and temporarily. This strategy has the effect of reduce overfitting. The percentage of nodes to dropout is fixed on Keras.
Python code for CNN architecture
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
y_train=np.array(y_train).astype('float32')
y_test=np.array(y_test).astype('float32')
x_train /= 255
x_test /= 255
# start of architecture Convolutional neural network
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(110, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.15))
model.add(Conv2D(84, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(84, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
# initiate RMSprop optimizer
opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-7)
# Let's train the model using RMSprop
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['accuracy'])
# checkpoint: save best model during teh training checkpoint
filepath=path+"weights.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=0, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
The data needed to estimate each of the neuron weights and connections should be as large as possible. As we mentioned above our dataset has only 3000 images, therefore we add an extra stage of “data augmentation”, where new images are created from the original dataset by incorporating slight modifications as rotations and translations.
By increasing the number of images,this stage allows us most of the time, to increase and to improve the robustness and quality of the model.
NB: TensorFlow/Keras propose several types of modification for “data augmentation”.
Run the CNN with data augmentation
#preprocessing and realtime data augmentation: data_generation = ImageDataGenerator( rotation_range=7, # randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.10, # randomly shift images horizontally (fraction of total width) height_shift_range=0.10, # randomly shift images vertically (fraction of total height) horizontal_flip=True, # randomly flip images vertical_flip=True) # randomly flip images data_generation.fit(x_train) # Fit the model model_param=model.fit_generator(data_generation.flow(x_train, y_train,batch_size=batch_size), steps_per_epoch=x_train.shape[0] // batch_size, epochs=epochs, validation_data=(x_test, y_test), callbacks=callbacks_list) #load best traning model model.load_weights(filepath)
Modifications in the “data augmentation” stage must be in accord with the dataset distribution, i.e. 90 degrees rotations might be conterproductive. Being given we want to predict if certain rooftop are horizontal or vertical. Therefore, only rotations less than 10 degrees should overcome some imperfection during learning stage.
NB: If the running time is too long, you can import the final model and its weights as below:
from keras.models import load_model model = load_model(path+'model.hdf5') model.load_weights(path+'weights_best.hdf5')
References
[1] ABADI, Martín, BARHAM, Paul, CHEN, Jianmin, et al. TensorFlow: A System for Large-Scale Machine Learning. In : OSDI. 2016. p. 265-283. [link]
[2] KRIZHEVSKY, Alex, SUTSKEVER, Ilya, et HINTON, Geoffrey E. Imagenet classification with deep convolutional neural networks. In : Advances in neural information processing systems. 2012. p. 1097-1105. [link]
[4] SCHMIDHUBER, Jürgen. Deep learning in neural networks: An overview. Neural networks, 2015, vol. 61, p. 85-117.[link]
[2] TOKUI, Seiya, OONO, Kenta, HIDO, Shohei, et al. Chainer: a next-generation open source framework for deep learning. In : Proceedings of workshop on machine learning systems (LearningSys) in the twenty-ninth annual conference on neural information processing systems (NIPS). 2015. [link]
[5] ZEILER, Matthew D. et FERGUS, Rob. Visualizing and understanding convolutional networks. In : European conference on computer vision. Springer, Cham, 2014. p. 818-833. [link]
Thanks a lot for sharing. Deep-learning is quite new for me. Thats allow to improve my understanding with this practical example.
Good afternoon, I am practicing with your soy from Ecuador, but I am totally new with neural networks of deep learning, I would like help to know how I can test an image with your algorithm.
m is not references anywhere before first use. please tell me how to procede. I think of it like the images object from glob.glob(path +”images”+”/*.*”).
Correct me if I’m wrong.
Hi Abdel !
Thank you for noticing this mistake.
I edited the code to make it work
Thanks for sharing. I tried executing the same code as is but the accuracy is just below 30%. Am I doing something wrong?
Hi Pavan,
-> Did you try to use tensorflow with a GPU or CPU ? (Some have notified me that with a cpu accuracy reaches approximately 0.30, while using their GPU it works well)
-> Usually you should have a significant improvement in approximately steps 20.
-> Have you tried to import the model and / or its weights?
Normally I do not read article on blogs, but I wish to say that this write-up very compelled me to take a look at and do it!
Your writing style has been amazed me. Thank you, quite great post.